
The Transformer: What’s Actually Inside ChatGPT
A simple way to understand the engine behind everything

LLMs for Engineers — Part 5
So far in this series, we’ve broken things down step by step. We started with where the data comes from, then saw how text becomes tokens, and then understood how the model predicts the next token again and again.

At this point, you already know how the system behaves from the outside. But there is still one big missing piece .What is actually inside the model that makes all of this possible?
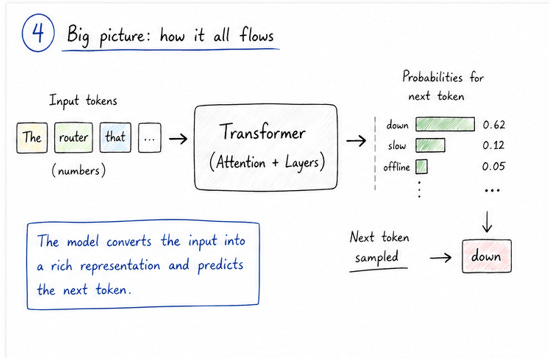
If we simplify everything, we can think of the model as a function. You give it a sequence of tokens, and it gives you probabilities for the next token. That’s the behavior we discussed earlier. But that function is not magic. It has a structure, and that structure is what we call a transformer.
Before transformers came into the picture, models used to process text step by step. They would read one word, then the next, and then the next. This worked, but it had clear limitations. It was slow, and more importantly, it struggled to handle long sequences. If something important appeared earlier in a sentence, the model would often lose track of it by the time it reached the end.
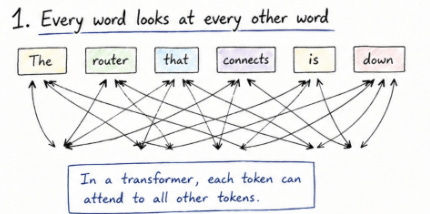
Transformers changed this completely by introducing a different way of looking at text. Instead of processing words one by one, they look at the entire sequence at the same time. This might sound simple, but it is a big shift. It means the model doesn’t have to “remember” things in the same way. It can directly look at any part of the input whenever it needs to.
To make this more concrete, think about a sentence like “the router that connects to the core switch is down”. When you read this, you naturally understand that “is down” refers to the router, not the switch. You connect different parts of the sentence without even thinking about it. The transformer is designed to do something similar, but using numbers.
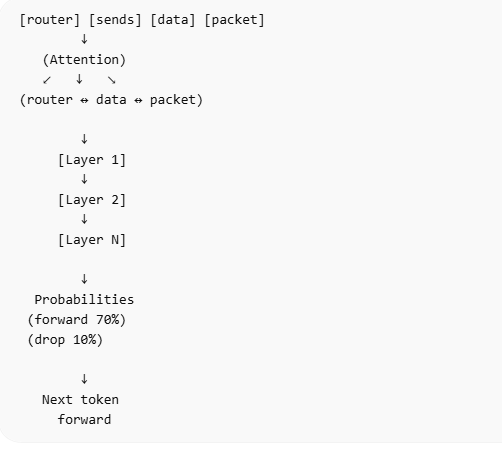
This is where the idea of attention comes in. Attention is the core mechanism inside a transformer. In simple terms, it means that for every token in the sequence, the model looks at all the other tokens and decides which ones are important. Not all tokens contribute equally. Some carry more useful information for the current prediction, and the model learns to focus on those.
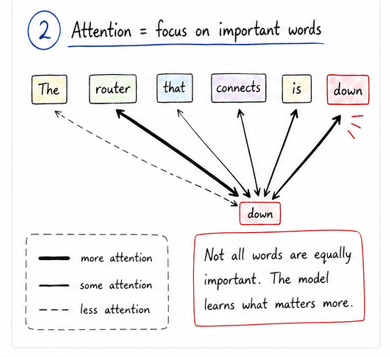
You can think of it like this. Each token is asking a question: “which other tokens should I pay attention to right now?” The model then assigns weights to all the tokens based on their importance. Tokens that matter more get higher weights, and those that matter less get lower weights. This creates a web of relationships across the entire sequence.
Once these relationships are established, the information flows through multiple layers inside the transformer. Each layer refines the representation a little more. At the beginning, the model might only capture very basic patterns. As we go deeper into the layers, it starts capturing more complex relationships and context. By the time we reach the final layers, the model has built a rich internal representation of the input sequence.
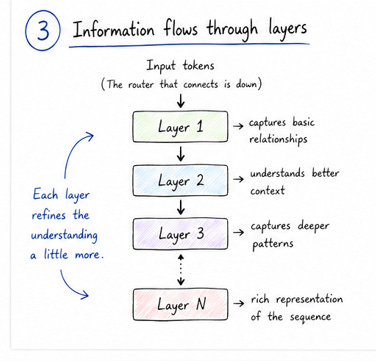
From there, the process is similar to what we discussed in the previous post. The model takes this refined representation and produces probabilities for the next token. So even though the core task is still next-token prediction, the transformer makes that prediction much more informed by understanding how tokens relate to each other.
One way to think about the transformer is that it allows every token to interact with every other token. Instead of a straight line where information flows from left to right, it creates a fully connected view of the sequence. This is why it works so well for language, where meaning often depends on relationships between words that may be far apart.
At this point, it’s important to remember something we’ve said before. Even with all this complexity, the model is not actually “understanding” language the way humans do. It is still working with numbers and patterns. What the transformer gives us is a much better way to capture those patterns, especially when context matters.
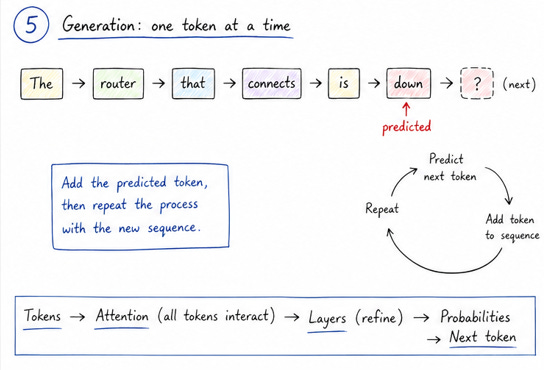
If you connect this back to the earlier posts, the full picture becomes clearer. We start with tokens, feed them into the transformer, use attention and layers to build relationships, and finally produce probabilities for the next token. That output is then sampled and added back into the sequence, and the process repeats.
So while the behavior of ChatGPT might feel complex from the outside, the core idea remains consistent. It is still predicting the next token, one step at a time. The transformer is simply the reason those predictions are so good.
Simple network architecture, the Transformer Link for reference
https://arxiv.org/abs/1706.03762