
How ChatGPT Actually Generates Answers (It’s Not What You Think)
A deep dive into the core engine behind LLMs

LLMs for Engineers — Part 4
So far in this series, we’ve talked about where the data comes from and how text gets converted into tokens.

That gives us the raw ingredients, but it still doesn’t explain the most important part how the model actually learns from all of this and how it ends up generating responses that feel surprisingly intelligent. If you strip everything away, what remains is a very simple objective, but one that becomes incredibly powerful at scale . The model is trained to predict what comes next.
To understand this properly, it helps to change how you think about the data. Instead of imagining documents, web pages, or structured knowledge, it’s better to think of the entire training dataset as one long continuous stream of tokens. There are no real boundaries in the way the model sees it is just sequences of numbers flowing endlessly.
In large systems, this stream can be on the order of trillions of tokens, but conceptually, it’s just a sequence where each token follows another. The model’s job is to observe this stream and learn the patterns that govern how tokens tend to follow each other.
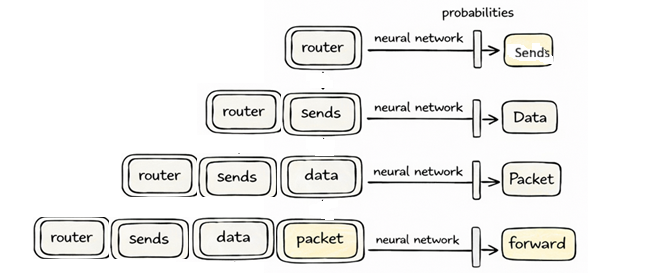
Now imagine we take a small slice of this stream. For example, something like “router sends data packet”.
[router, sends, data, packet]This slice is what we call the context. The training task is surprisingly straightforward: given this context, predict the next token. In this case, a reasonable continuation might be “forward”.
But instead of directly outputting the word “forward”, the model produces a probability distribution over all possible tokens in its vocabulary. So it might assign a higher probability to “forward”, a slightly lower probability to “drop”, and smaller probabilities to many other tokens. At the beginning of training, these probabilities are essentially random because the model hasn’t learned anything yet.
At this point, it helps to pause and visualize what is actually happening. The entire learning process can be reduced to a simple flow a sequence goes in, probabilities come out, and the model moves toward the correct answer.
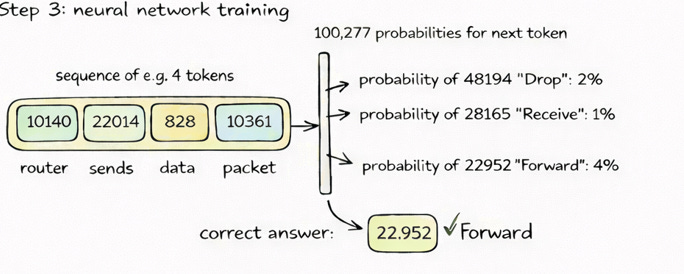
If you look at the diagram, you can see exactly what we just described. A sequence of tokens such as “router sends data packet” is fed into the neural network, which then produces probabilities for the next token. The correct answer in this case “forward” is already known from the dataset, and the model is adjusted so that its probability increases. This process is repeated over and over again, across massive amounts of data, gradually shaping the model’s internal parameters.
This is where the learning actually happens. Since we already know the correct next token from the dataset, we can compare the model’s prediction with the actual answer. If the model assigned a low probability to the correct token, we adjust its internal parameters slightly to increase that probability and decrease the probabilities of incorrect tokens. The adjustment itself is very small, almost negligible in isolation, but when you repeat this process across millions of sequences and eventually trillions of tokens, the model begins to capture meaningful structure in the data.
What’s important here is that the model is not learning rules in the traditional sense. It is not explicitly told that routers forward packets or that certain facts must always hold true. Instead, it is learning statistical relationships between tokens based on how frequently they appear together. If a particular sequence shows up often enough, the model encodes that relationship into its parameters. Over time, these relationships become strong enough that the model’s predictions start to look intelligent, even though they are fundamentally based on probabilities.
If we look inside the model, things become more mathematical but not necessarily more mysterious. At its core, the model is simply a function that maps input tokens to output probabilities. Internally, this involves a series of matrix multiplications, additions, and nonlinear transformations applied across many layers. The behavior of this function is controlled by its parameters often billions of them which are adjusted during training. You can think of these parameters as knobs that are gradually tuned so that the model produces better predictions over time.

Once training is complete, the model stops learning and switches to what we call inference, which is what happens when you interact with it. Suppose you type “router sends data”. The model processes this input and predicts a probability distribution for the next token. It might assign high probability to “packet”, but instead of always choosing the highest probability token, the model samples from this distribution. This introduces a controlled amount of randomness, allowing the model to produce more varied and natural responses.
Again, it helps to visualize what is happening during generation. The diagram shows this process clearly. Instead of updating the model, we now repeatedly feed the growing sequence back into the network and sample one token at a time.
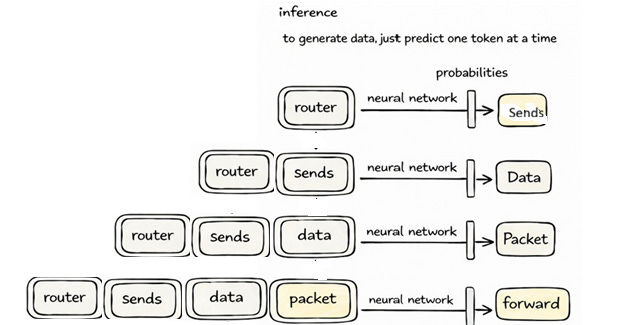
Each step looks simple in isolation, but together they form a loop. The model takes the current sequence, predicts the next token, appends it, and then repeats the process. So “router sends data” becomes “router sends data packet”, then “router sends data packet forward”, and so on. What looks like a complete sentence to us is actually built one token at a time through this iterative process.
This also explains many of the behaviors people observe when using models like ChatGPT. Because the model is generating text based on probabilities rather than verifying facts, it can sometimes produce outputs that sound confident but are incorrect. Similarly, because sampling introduces randomness, the same input can lead to slightly different outputs on different runs. These are natural consequences of how the system works, not anomalies.
One useful way to think about the model is as a compressed representation of the data it was trained on. It doesn’t store exact copies of the internet, but it captures patterns in a highly condensed form within its parameters. When generating text, it reconstructs these patterns in new combinations, which is why it can produce both familiar and novel outputs.
If there’s one idea to take away from all of this, it’s that ChatGPT is fundamentally a next-token prediction system operating over sequences of tokens. Everything else the fluency, the apparent reasoning, and the usefulness emerges from this simple mechanism applied at massive scale. Once you internalize this, many of the behaviors of large language models start to make much more sense.
In the next post, we’ll build on this foundation and explore how a base model, which is essentially just a next-token predictor, gets transformed into something that behaves like an assistant — following instructions, answering questions, and interacting in a helpful way. That’s where alignment and post-training come into the picture, and it’s what turns a raw model into something like ChatGPT.
Smiles :)
Anurudh