
The Core Engine: How AI Learns and Predicts the Next Token
From internet text → patterns → probabilities → generation

LLMs for Engineers — Part 4
Welcome back to our LLM Journey. If you are new to here , don’t miss to check previous posts before diving into this post.
So far, we’ve built the pipeline:
Internet → filtered data
Data → tokens (numbers)

Now comes the most important step:
👉 How does the model actually learn from this data?
🧠 Step 1: What the model actually sees
After preprocessing + tokenization:
👉 The entire internet becomes:
[1543, 9281, 77, 201, 9912, ...]
Important realization
This is NOT:
sentences
paragraphs
knowledge
👉 It is just a long sequence of tokens
In real systems:
👉 ~15 trillion tokens
Think like this
It’s like:
👉 A massive “stream of language”
And the goal is:
👉 Learn how this stream flows
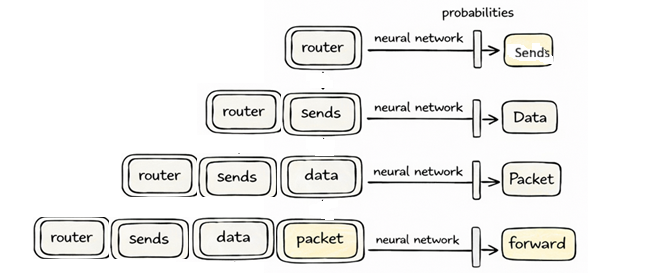
🧩 Step 2: Create training examples (windows)
We don’t feed everything at once.
We take small chunks:
[router, sends, data, packet]
This is called:
👉 Context
The task
Given this:
👉 Predict next token
Example
router sends data packet → ?
Correct answer:
👉 “forward”
👇 Now visualize what happens
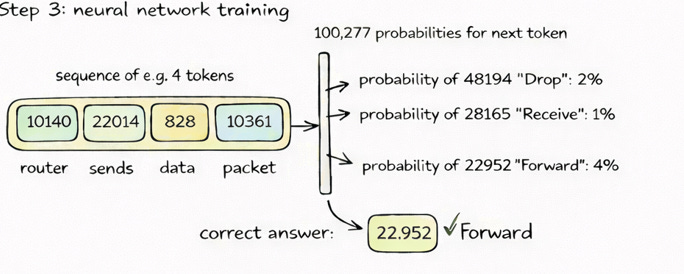
⚙️ Step 3: Model makes predictions
The neural network outputs:
👉 Probability for EVERY token (~100K)
Example:
forward → 4%
drop → 2%
receive → 1%
Important ⚠️
At start:
👉 These are RANDOM
Because:
👉 Model starts with random parameters
🔧 Step 4: Compare with correct answer
We already know:
👉 Correct = “forward”
Goal
👉 Increase its probability
👉 Decrease others
🔁 Step 5: Update the model
This is the key idea from transcript:
We “nudge” the model slightly toward correct answers
Think like this
🎛️ Model = billions of knobs
Training = adjusting them slightly
🔄 Step 6: Repeat at massive scale
This process happens:
across trillions of tokens
in parallel
millions of times
What is happening?
👉 Model is learning:
Statistical patterns of token sequences
Example patterns learned
“capital of France” → Paris
“router sends data” → packet
“once upon a” → time
⚙️ Step 7: What is inside the neural network?
Let’s simplify :

It’s just a function
👉 Input → Output
Input:
👉 Token sequence
Inside:
matrix multiplications
additions
transformations
Output:
👉 100,000 probabilities
Key idea
It’s a giant mathematical expression
Parameters
👉 Billions of numbers
Before training:
👉 Random behavior
After training:
👉 Pattern-aware behavior
🧠 Important insight (VERY IMPORTANT)
The model does NOT learn:
facts
rules
logic
It learns:
👉 what usually comes next
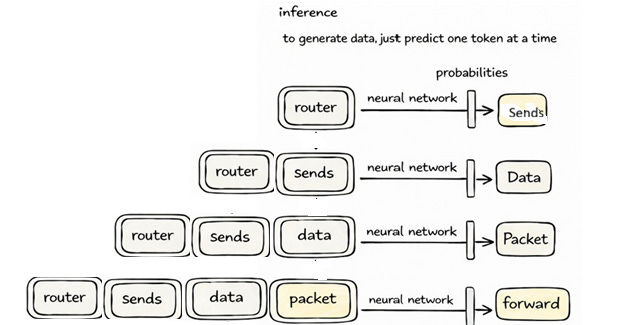
🔮 Step 8: Inference (Generation)
Now training is DONE.
Model is frozen.
Now what happens?
You give input:
router sends
Step-by-step
Step 1:
Predict next token → “data”
Step 2:
Append → “router sends data”
Step 3:
Predict → “packet”
Step 4:
Repeat…
👇 Visualize this loop
🎲 Step 9: Sampling (critical concept)
The model does NOT always pick:
👉 highest probability
It samples
Think:
👉 rolling a weighted dice
Result
Same input:
router sends data
Can produce:
packet forward
packet to destination
packet via protocol
⚠️ This explains EVERYTHING
From transcript:
👉 Model is stochastic
That’s why:
outputs vary
hallucinations happen
creativity exists
🤯 Step 10: Why it feels intelligent
Because:
👉 It has compressed internet patterns into weights
Key idea
Model is like a lossy compression of the internet
Meaning
It doesn’t store exact data
It stores patterns
⚠️ Reality check
The model is NOT:
thinking
reasoning
verifying
It is:
👉 Predicting what is likely next
🧠 Engineer’s mental model
Think of it like:
Data → token stream
Model → probability engine
Output → sampled token
Loop → repeat
🔁 Training vs Inference
Training:
👉 Learn patterns
Inference:
👉 Generate sequences
💡 One powerful takeaway
ChatGPT = trained probability machine over token sequences
🚀 What’s coming next
Now we understand:
how models learn
how they generate
But something is missing…
👉 Why does ChatGPT behave like an assistant?
🔜 Next in this series
👉 Base model → ChatGPT (alignment & post-training)
If you truly understood this post…
👉 You now understand 80% of how LLMs work.
Let’s go deeper 🚀
SMiles:)
Anurudh