

LLMs for Engineers — Part 2
In the last post, we uncovered something surprising:
ChatGPT is just predicting the next word.
When people first hear about ChatGPT, one of the most common questions is this: where does it actually learn all of this from? It can answer questions, explain concepts, write code, and even sound conversational. So it’s natural to assume there must be some kind of structured knowledge base behind it.
But that’s not really how it works.
At its core, the model learns from a massive amount of text data. Not neatly organized knowledge, not curated lessons, but raw text collected from across the internet. This includes things like articles, blogs, forums, documentation, and code. The idea is simple — if you expose a model to enough examples of how language is used, it can start picking up patterns. And once it learns those patterns, it can generate similar text on its own.
But this doesn’t mean the model is just blindly copying the internet. The process is more structured than that.
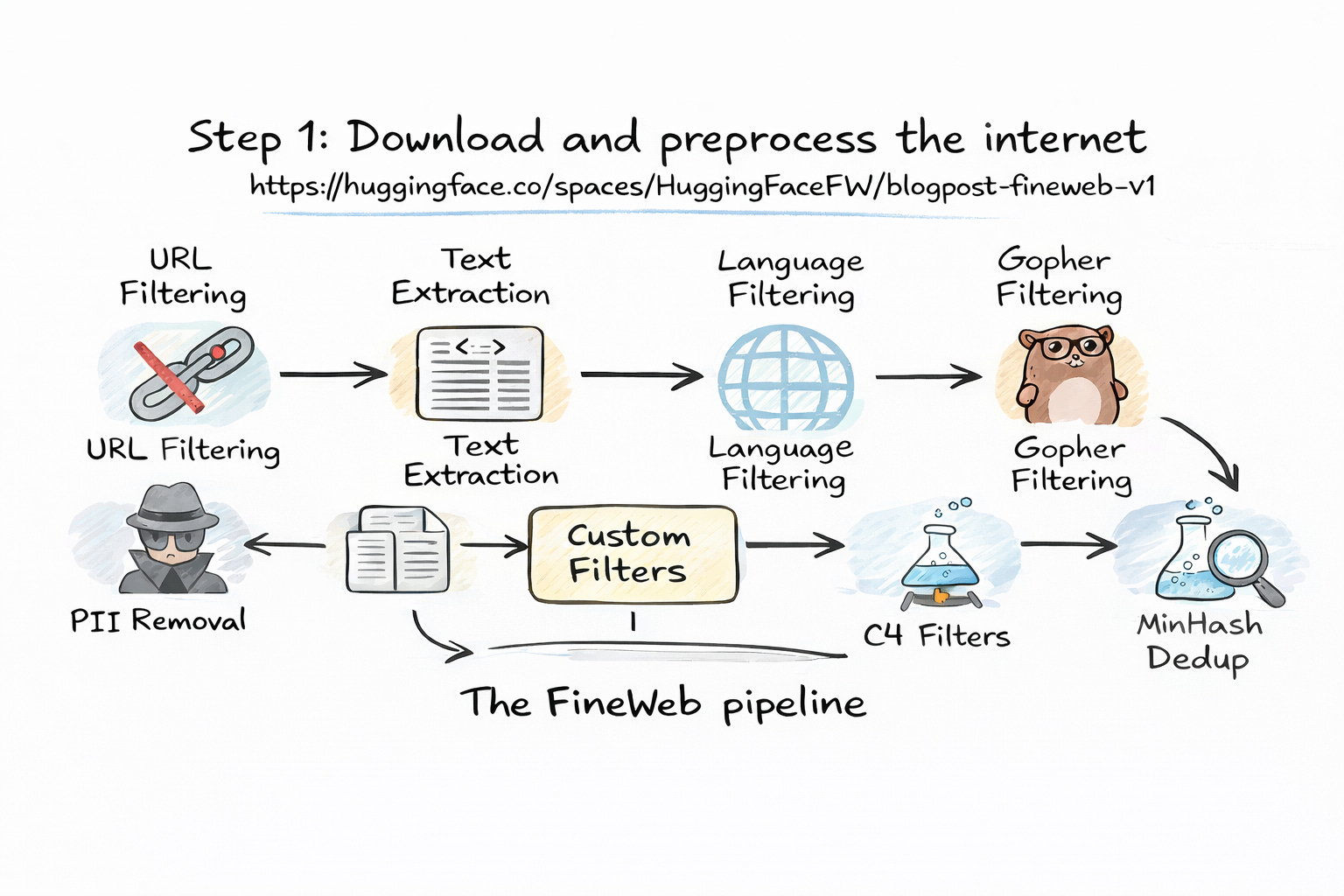
A large part of this data comes from datasets like Common Crawl, which has been collecting web data for years. You can think of it like a system that starts from a set of websites, follows links, and keeps collecting content along the way. Over time, it builds a huge snapshot of the web. But this raw data is messy. It contains everything —useful content, ads, broken pages, scripts, and a lot of noise.
So before any training happens, this data goes through heavy cleaning.
At this point, it helps to think about what we actually want the model to learn from. If we feed it entire web pages as they are, it will learn patterns from things we don’t care about navigation menus, pop-ups, or random scripts. That’s not useful. So the first step is filtering out bad or irrelevant sources. Websites that are spammy, unsafe, or low quality are removed early on.
Once that is done, the next step is extracting the main content. This means stripping away all the extra parts of a webpage and keeping only the meaningful text. If you’ve ever used a “reader mode” in your browser, it’s a similar idea. We only want the actual content, not the surrounding clutter.
After that comes language filtering. Since most large models are trained primarily on English, the system checks whether the text is mostly in English. If a page doesn’t meet a certain threshold, it might be excluded. This step directly affects what languages the model becomes good at.
Then comes deduplication, which is more important than it sounds. The internet has a lot of repeated content copied articles, mirrored pages, or slight variations of the same text. If the model sees the same thing again and again, it doesn’t learn anything new. So duplicates are removed to make the dataset more useful.
Finally, there is filtering for sensitive information. Things like personal data, phone numbers, or credit card details are removed. This step is important for safety and privacy.
If you step back and look at all this, the process is actually quite logical. We start with a huge amount of raw data, then clean it step by step until we are left with mostly useful text. What remains is not perfect, but it’s good enough for the model to learn patterns from.
Even after all this filtering, the dataset is still enormous. We are talking about tens of terabytes of text. That’s far beyond what any human could read in a lifetime. And that scale is what makes these models powerful. The more data they see, the better they get at capturing how language works.
But here’s an important point that is easy to miss.
The model is not learning facts in the way we think. It is not storing information like a database. Instead, it is learning patterns in how words and sentences are used. If something appears frequently in the data, the model becomes more likely to generate it. If something is rare or inconsistent, the model is less confident about it.
So when you ask a question, the model is not retrieving an answer from memory. It is generating a response based on patterns it has learned from all this data.
That’s a subtle but very important difference.
You can think of this entire process as building the “experience” of the model. Just like humans learn language by reading and listening over time, the model learns by seeing massive amounts of text. The difference is scale ,the model sees far more data than any human ever could.
And this is just the first stage.
Because even after learning from all this data, the model is still not ChatGPT yet. It has learned patterns, but it doesn’t know how to behave like an assistant. That part comes later.
In the next post, we’ll zoom in further and understand how this text is actually represented inside the model. Because before the model can learn patterns, it needs to convert everything into a form it can work with.
And that’s where tokens come in.
Smiles :)
Anurudh