
How AI Actually Reads Text (It Doesn’t See Words)
A simple way to understand what really goes inside the model

LLMs for Engineers — Part 3
Welcome back to our LLM Journey. If you are new to here , don’t miss to check previous posts before diving into this post.
So far, we’ve seen:
ChatGPT predicts the next word
It learns from internet-scale data

Most of us assume that AI reads text the same way we do. We see words, sentences, and meaning. So it’s natural to think that models like ChatGPT also process language in a similar way.
But that’s not what’s happening at all.
In fact, the model doesn’t see words. It doesn’t see sentences either. What it actually sees is something much more basic numbers.
To understand this properly, it helps to zoom in a bit.
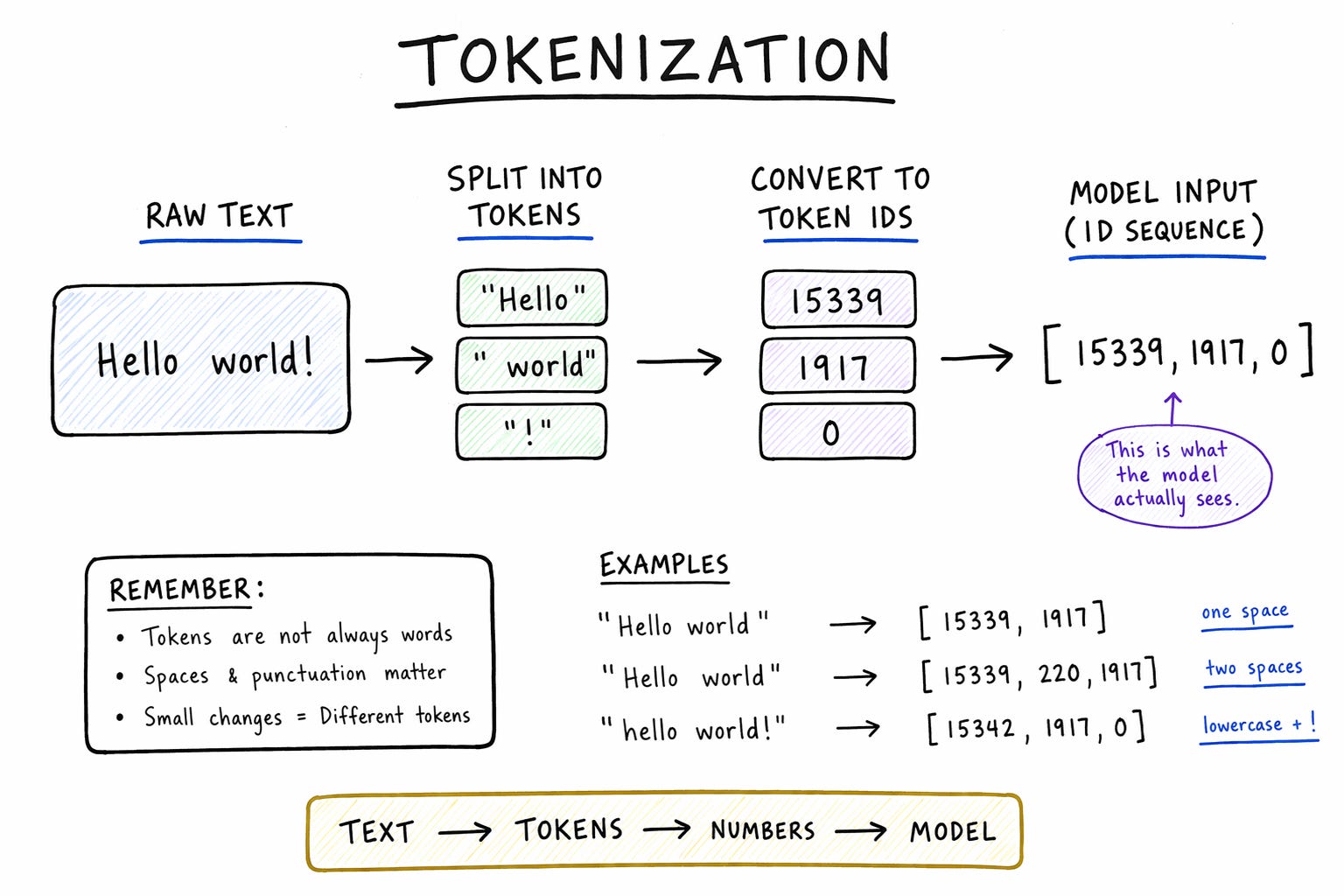
Take a simple sentence like “router sends data”. When you read it, you instantly understand what it means. But a computer can’t work with text directly. The first thing it does is convert everything into a numerical form. At the lowest level, this means turning characters into bytes, and bytes into numbers. So even before we talk about AI, the sentence is already transformed into a long sequence of numbers.
Now here’s the problem. If we keep everything at the character or byte level, the sequence becomes very long and inefficient. And in models like these, sequence length matters a lot. Longer sequences mean more computation, more cost, and slower processing. So we need a better way to represent text.
This is where tokenization comes in.
Instead of working with individual characters, the model groups pieces of text into units called tokens. You can think of tokens as chunks of text that are more efficient to work with. Sometimes a token is a full word, sometimes it’s part of a word, and sometimes it even includes spaces or punctuation.
For example, the sentence “router sends data” might be broken into tokens like:
[router, sends, data]Each of these tokens is then mapped to a unique number. So what the model actually sees is not the words themselves, but something like:
[1532, 8471, 2983]
These numbers are just IDs. They don’t carry meaning by themselves. They are simply a way to represent text in a format the model can process.
At this point, it might feel like we’re losing information, but we’re actually making things more efficient. By using tokens, we reduce the length of the sequence while still keeping important patterns intact. Common patterns like “data”, “packet”, or “forward” can become single tokens, while rare or complex words can be broken into smaller pieces. This balance is what makes tokenization powerful.
A natural question here is: how does the model decide what becomes a token?
The idea is surprisingly simple. We look at large amounts of text and find patterns that appear frequently. If certain combinations of characters show up again and again, we merge them into a single token. Over time, this builds a vocabulary of tokens that covers common patterns in language. This process is often done using methods like Byte Pair Encoding, but you don’t need to worry about the details. The key idea is that tokens are designed to make text both compact and flexible.
If you want to really understand this, it helps to try it yourself once.
Go to:
👉
https://tiktokenizer.vercel.app/?model=cl100k_base
Type something simple like “router sends data”.
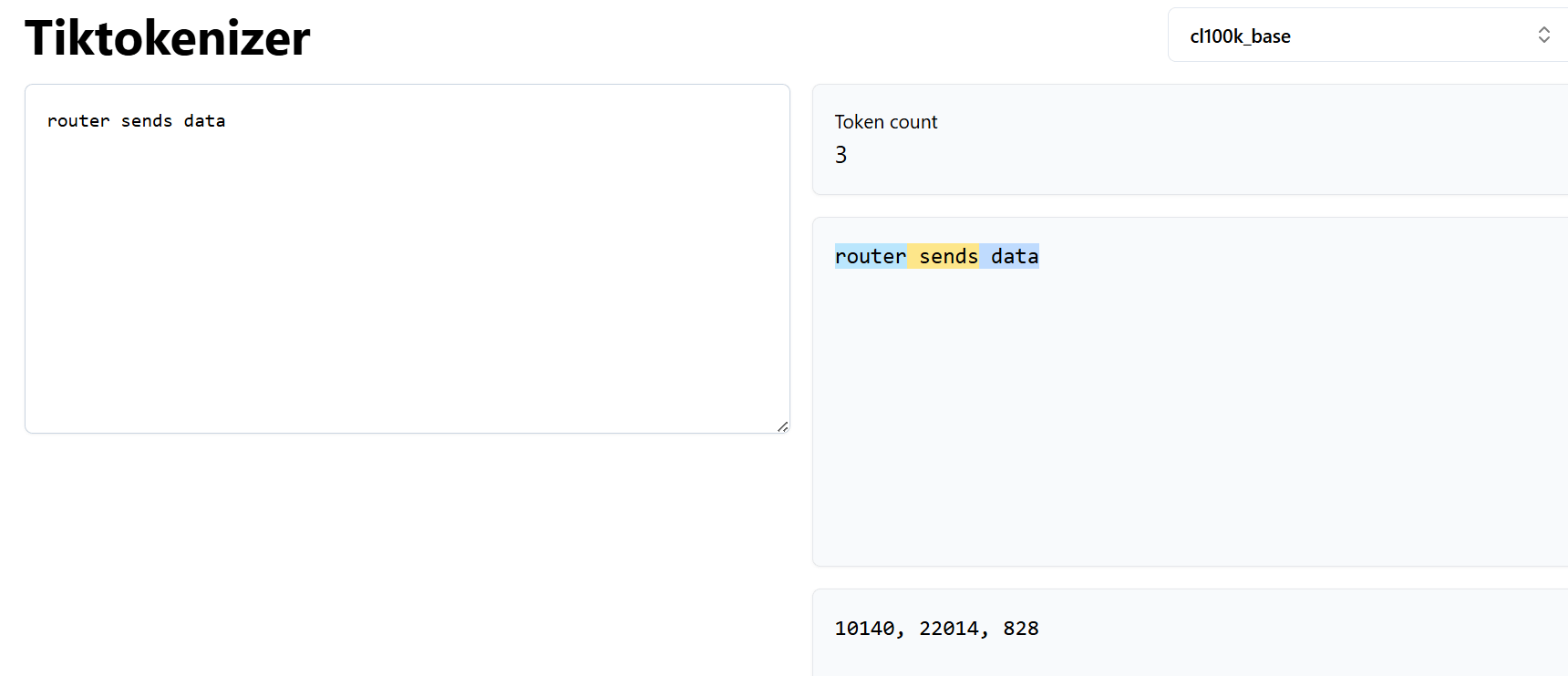
Now try small changes. Add an extra space. Change the case. Add punctuation. You’ll notice that the tokens change. Sometimes even a tiny change in text leads to a completely different token sequence.
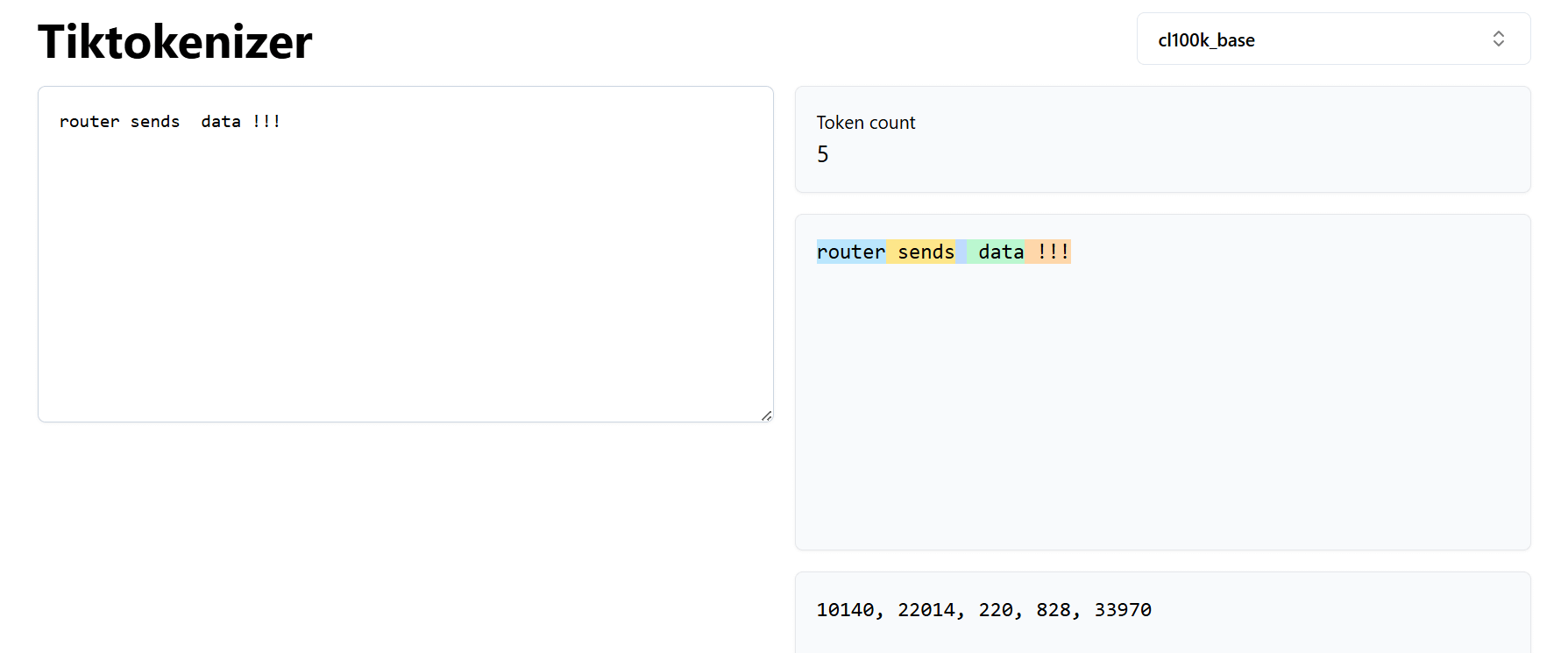
This is an important moment.
Because what you type is not what the model sees.
The model only sees tokens.
That means when you change your prompt even slightly ,you are actually changing the sequence of tokens going into the model. And that can change the output.
This explains a lot of things people notice when using AI. Why small wording changes affect responses. Why formatting matters. Why sometimes adding or removing a word changes everything. It’s all happening at the token level.
If you like networking analogies, you can think of this like packetization. Before sending data over a network, we break it into packets. Here, before feeding text into a model, we break it into tokens. The model doesn’t see the original message it sees the encoded form.
So when you write a prompt, you’re not really writing for a human. You’re designing a sequence of tokens for a machine.
And that sequence is what drives everything that comes next.
In the next post, we’ll build on this idea and see what the model actually does with these tokens. Because once text becomes tokens, the next step is where the real magic — or more accurately, the math — begins.